---
title: Zabbixで LinuxのソフトウェアRAIDを監視する
description: ハードディスクの故障を検知しなければRAIDは意味をなさない
date: 2021-05-30
image: zabbix.jpg
---
(この記事はそうとう昔に書かれたものを拾い出して復活させたものだが、元の日付が不明なため復活時の日付が付けられている)
## RAIDについてのよくある誤解
ハードディスクが故障してシステムが停止したりデータが消失したりするリスクを低減するために 複数のハードディスクに同じデータを持つ冗長化の仕組みとしてRAIDが用いられる。最近は市販の製品にも搭載されているため比較的よく知られるようになったと思うが、その意味については誤解されていることも多いように見受けられる。
RAIDは、
- × ハードディスクが壊れなくなる仕組み
- ○ ハードディスクが壊れても新しいものに__交換する時間的猶予が与えられる__仕組み
なので、RAIDを構成するハードディスクのひとつが壊れた時には即時にそれが何らかの方法で人間に知らされなくてはならない。(それにより人間はハードディスク交換というアクションを起こす)
一般的にハードウェア RAIDの場合は、RAIDを構成するハードディスクに障害が起こりデグレード状態になるとブザー音などの警告でユーザーに問題を通知するため見逃しは起こりにくいのだが、ソフトウェア RAIDの場合はそのような場合でも静かに稼働してしまったりして問題に気付きにくい。
LinuxのソフトウェアRAID管理ツール mdadmにはアレイがデグレードすると警告メールを送信する機能があるのでそれを使用して警告メールを送信する手もあるのだが、監視専門のツールを利用できるのであればそれを使って一括して監視してしまう方が良い。
なのでオープンソースの統合監視プラットフォームとして知られる [Zabbix](http://www.zabbix.com/jp/) で LinuxのソフトウェアRAIDを監視してみることにする。
## どこを監視すればいいか
RAIDの稼働状況は /proc/mdstat から知ることが出来る。例えば、4TBのハードディスク2台をRAID1で構成したアレイ(ここではシステム上 md127と名前がついている)がひとつ正常に稼働している時の内容はこのようになっている。
```text
Personalities : [linear] [raid0] [raid1] [raid10] [multipath] [faulty] [raid6] [raid5] [raid4]
md127 : active raid1 sdb1[0] sdc1[1]
3906885440 blocks super 1.2 [2/2] [UU]
```
ハードディスクの読み書きに問題が起こって OSがアレイをデグレード状態であると認識すると、この内容が変わる。具体的には、__[UU]__の部分が [U_] などになったりする。なので、__このカギ括弧の中に "U" 以外の文字が無ければ健常__という判断でよさそうだ。egrepと wcで健常な RAIDアレイの数をカウントしてみよう。
```sh
egrep '[0-9]+ blocks (.* )?\[[0-9]+/[0-9]+\] \[U+\]' /proc/mdstat|wc -l
```
稼働しているRAIDアレイ数が1つであれば実行結果は1と表示される。
## エージェント側の設定
監視対象となるホストには Zabbixエージェントがインストールされており、既にエージェント監視が行われているものとする。設定ファイル /etc/zabbix/zabbix_agentd.conf に上の実験結果をふまえこのような行を追加する。
```text
UserParameter=raid.healthy,egrep '[0-9]+ blocks (.* )?\[[0-9]+/[0-9]+\] \[U+\]' /proc/mdstat|wc -l
```
これで、監視サーバから raid.healthy という監視パラメータ名で健常なRAIDアレイの稼働数を取得できるようになる。(監視パラメータ名は好きなものを付けて良い)
設定ファイルを変更したら Zabbixエージェントを再起動する。
## 監視サーバ側の設定
「設定」→「ホスト」からホストのアイテム一覧を開き、「アイテム作成」で監視項目を追加する。
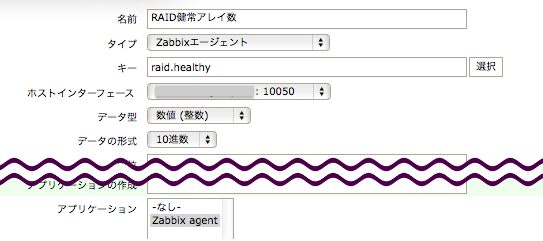
「監視データ」→「最新データ」から新しく追加された項目の状態を確認できる。

後は「健常状態であるべきRAIDアレイの数が違う時」に対してトリガーとアクションを設定すれば、然るべき方法でアラートを上げることが出来るだろう。